Meta超大规模AI智算基础设施架构设计

摘要
- 双重 GPU 集群,每群配备 2.4 万个 H100 芯片,分别采用 RoCE 和 InfiniBand 网络连接。
- LLaMA3 就是在这两个集群上训练出来的;
- Meta AI 将部署庞大算力集群,拥有 35 万张 H100 GPU,相当于 60 万张 H100 的总算力,助力突破性人工智能研究。
Meta打造两个庞大AI集群,每个集群拥有2.4万张GPU。该设计专注于计算、网络和存储的无缝集成,旨在推动人工智能的未来发展。
1 第一代 GPU 集群:1.6w A100 (RSC)
Meta 自 2022 年起公开其强大的 AI 基础设施,率先推出 Research SuperCluster (RSC),该集群由 16,000 个 A100 GPU 组成。RSC 为 Meta 的 AI 研究和开发提供了无与伦比的计算能力。
RSC为Meta AI开发提供技术支持,助力其构建将生成式AI融入各类应用,如计算机视觉、NLP、语音识别、图像生成和编码。RSC的先进能力显著提升了Llama/llama2等AI模型的训练效率。
2 第二代 GPU 集群:2.4w H100
精确数字是每个集群 24,576 张 H100 GPU。
Meta新一代 AI 集群充分吸收了 RSC 的成功和经验教训,这包括,
- 新集群能支持更大、更复杂的模型,为GenAI产品开发和AI研究的进步铺平了道路。
Meta 自研关键技术,搭建先进基础设施,每天高效执行万亿级 AI 任务。端到端优化确保数据中心高效运行,支撑着 Meta 的 AI 创新。

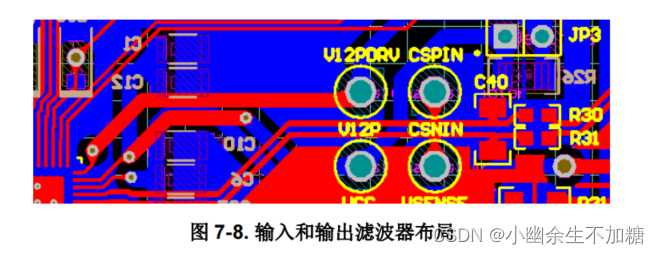
左侧:计算机柜,包括GPU服务器机框、fabric交换机等等;右侧:存储机柜。
2.1 计算:Grand Teton GPU 主机
双新集群采用 Grand Teton,这是 Meta 开发的一种开放的 GPU 硬件平台,已贡献给开放计算项目 (OCP)。
从2015年的Big Sur平台开始,Meta一直在开放设计GPU硬件平台。
Grand Teton 实物图如下,

- 提供了快速可扩展性和灵活性,设计简化,可以快速部署到数据中心,并易于维护和扩展。
创新的Open Rack电源和机架架构相结合,可迅速构建和定制Meta当前和未来的集群,满足不断增长的应用程序需求。
2.2 网络
两个集群使用了不同的网络方案,但都是 400Gbps 接入。
2.2.1 集群一:400Gbps RoCE + 自研交换机
基于 RoCE 网络,使用的交换机包括
- 自研置顶交换机(TOR)Wedge400 / Arista 7800 ,
- 自研模块化交换机 Minipack2。
- Minipack/Minipack2 多用途交换机,可灵活部署为 Spine 交换机,满足不同组网需求。
- Minipack 创新(2019 年),重塑 Facebook 数据中心网络,为下一代数据基础设施树立了新标杆。
- 早期的数据中心网络:
Facebook 的下一代数据中心网络:“数据中心 Fabric”(2014 年)
2.2.2 集群二:400Gbps InfiniBand
使用NVIDIA Quantum2 InfiniBand fabric。
2.2.3 小结
在评估大规模训练中的 RoCE/IB 适用性和可扩展性时,对比研究表明:
RoCE 和 IB 组网的集群均可处理大型生成式 AI 任务,例如 Llama 3 的训练,且未遇网络限制。
这些发现为构建更大规模集群提供指导,有助于解决大型生成式 AI 训练模型的网络挑战。
2.3 存储
存储在 AI 训练中扮演着重要角色,然而相关的讨论确非常少。
人工智能任务的多模态性推动了对高性能存储的需求。理想的解决方案应提供卓越性能,并在处理图像、视频和文本时保持低能耗。
2.3.1 数据和 checkpoints 存储:FUSE + Tectonic
AI 集群的数据和 checkpoint 的存储方案:
- 上层是一个自研的 Linux 用户空间文件系统(FUSE)
- Tectonic,Meta 的分布式存储解决方案,专为闪存优化,为数据密集型应用程序提供无与伦比的性能和效率。
这个解决方案使得
- 同时还提供了 EB 级存储系统所需的灵活性和高吞吐。
2.3.2 交互式调试:Parallel NFS
与 Hammerspace 合作开发的并行 NFS 系统,可支持数千个 GPU 的交互式调试。代码改动能瞬间同步到环境中的所有节点,显著提升调试效率。
Tectonic 分布式存储与 Hammerspace 相结合,释放了企业数据快速迭代的潜能,同时打破了规模限制。
2.3.3 大容量 SSD + 定制每个机柜的服务器数量
Tectonic 和 Hammerspace 解决方案均采用 YV3 Sierra Point 服务器平台,集成了市场上最先进的高容量 E1.S SSD,提供卓越的性能和存储容量。

OCP 服务器如同乐高积木,赋予存储层灵活扩展性,满足未来 AI 集群的增长需求,且不影响日常维护和操作,为数据中心提供敏捷高效的基础架构。
3 性能
3.1 原则:性能和易用性缺一不可
构建 AI 集群的关键是兼顾性能与易用性,避免顾此失彼。这种均衡至关重要,因为它确保了训练出卓越的 AI 模型。
优化大型系统设计的最佳方法是通过迭代构建和测试。小集群和大型集群的性能比较可以帮助识别瓶颈。下图以消息大小为横轴,归一化带宽(0-100)为纵轴,展示了当大量 GPU 交互时 AllGather 性能随集群规模的变化。
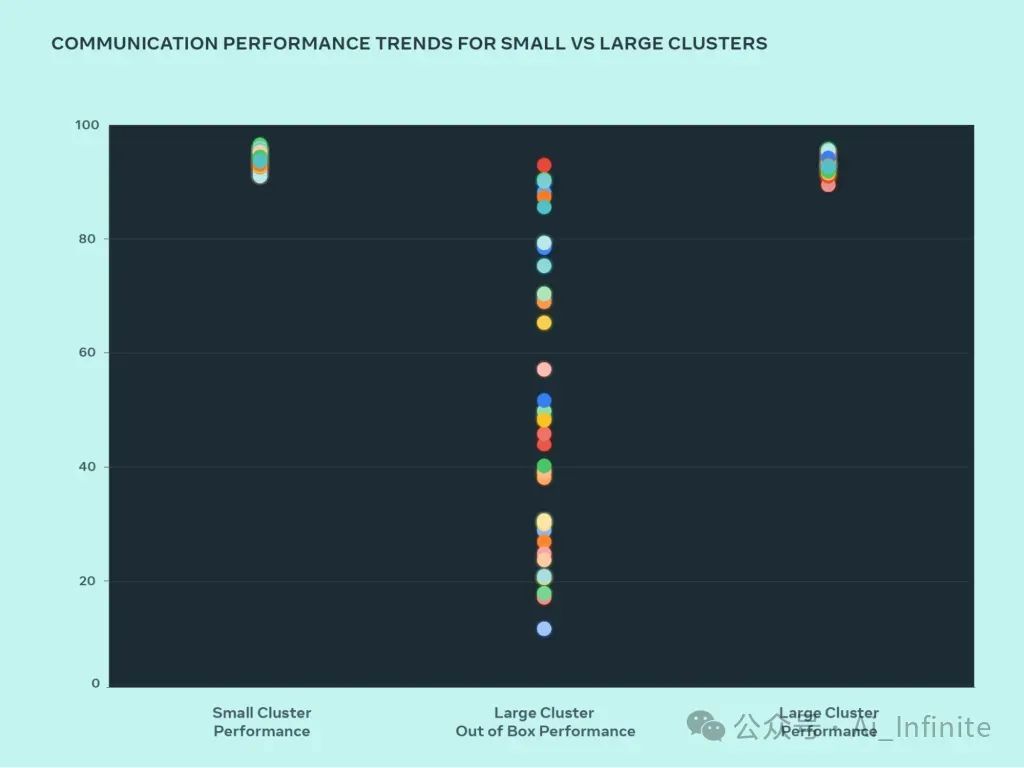
优化前:小型集群性能优异(90%+),大型集群性能低下(10%-90%)。
优化后:通过系统化优化,大型集群性能飙升至理想的90%+,与小型集群齐头并进。
3.2 大集群优化
优化大型集群性能:
* 通过减少wait time提升性能85%。
* 优化hash slot分配方式提升性能15%。
- 改进 job scheduler,使其具备网络拓扑感知能力,这带来的好处:
- 延迟降低
- 转发到更上层网络(交换机)的流量减少。
- 结合 NVIDIA NCCL,优化了网络路由策略,以实现最优的网络利用率。
以上两项优化使大集群的性能已经接近小集群。
- 与训练框架和模型团队密切合作,不断改进基础设施。例如,
- 并行技术优化,
- 存储优化,
- 可调试性是大型训练的主要障碍,在大规模情况下难以追踪拖慢训练进程的卡顿原因。
为此,正在开发 desync 调试和分布式飞行记录等工具,用于跟踪分布式训练流程,快速识别问题。 - PyTorch 优化显着提升训练速度:
通过优化进程组初始化,PyTorch 可支持数万至数十万 GPU 并行训练。优化前,启动时间可长达数小时,优化后缩减为几分钟。
4 对Open AI innovation的承诺
Meta 坚信开源技术的力量,旨在通过开放创新来解决行业难题:
- Meta 坚定地致力于开源硬件和软件。
- 相信开源社区可加速 AI 领域的进步。
- 持续支持开放硬件创新,成为 OCP 创始成员,已将 Grand Teton 和 Open Rack 等设计贡献给社区,共创未来。
- 作为PyTorch的最大和主要贡献者,继续推动这一AI软件框架的开发和普及。
- 继续致力于 AI 研究社区的开放创新。
- 汇聚 AI 先锋,探索负责任的 AI 发展。我们倡导在开发大模型和大语言模型等技术时,坚持道德准则和社会影响考量。
- 联手 AI Alliance,一个领先 AI 组织组成的联盟,加速负责任的 AI 创新,开启开放社区的无限可能。
AI 工作建立在开放科学和协力合作的哲学之上。
5 未来展望
Meta为其未来 AI 愿景打造了两个强大的 AI 训练集群。到 2024 年底,Meta 将拥有 35 万张 H100 GPU,总算力相当于 60 万张 H100,为其 AI 创新奠定了基础。
持续优化基础设施,从硬件到业务层面,确保灵活可靠。评估和改进流程以满足不断演变的需求,支持创新模型和研究,打造未来准备就绪的系统。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-